Summary
The industry is touting a recent SparkToro article by SEO OG, Rand Fishkin, describing AI tracking tools as “selling a boondoggle of snake oil chicanery”. It was a solid read; an absolute masterclass in knowing one’s audience and writing a compelling advertorial. It took a minute to process, but I was in awe. He took two of my favourite things, rhetoric and research, and executed them like the seasoned marketing pro that he is.
Each argument and corresponding statement was beautifully presented and reinforced—some by data, others by well-constructed rhetorical devices. Here’s the crux of the article:
- Popular AI visibility tools are an expensive waste of budget. Anyone using these can’t be a serious marketer.
- Because LLMs, like ChatGPT, are wildly inconsistent when presenting results.
- We should probably track visibility, though… since it’s the only meaningful metric we currently have.
- So try my friend Patrick’s tool instead. It has a free plan. LOL.
Ok, you caught me. I added the LOL in for effect.
Let’s break this down further.
Know your audience
The majority of search professionals would agree the industry is in the process of a seismic shift. Google, the Galactus of search, has had a stranglehold on your marketing dollars for more than two decades. Bing, its closest competitor, took over 10 years to pry 4% of marketshare.
While the numbers I’ve read vary, an aggressive estimate would say that around 20%—or a whopping 1 in 5—searches now happen outside of Google’s ecosystem. This number is even more impressive when you factor in that Gemini is ChatGPT’s closest competitor.
As early as April 2025, I saw purported GEO (or AIO, AEO, LLMO) experts emphasizing the end of SEO. On the other side of the spectrum, SEOs have been arguing that GEO=SEO. While both claims are incorrect, the latter has some traction. There was, and is, a lot of misinformation going around, which is to be expected at the onset of an evolving discipline. The organic search community is rattled, and understandably so. Change can be daunting and most service-based professionals feel that there is an AI-shaped target on their backs.
The pervasive thought amongst SEOs practitioners was that there was nothing to see here. GEO is merely a shiny new acronym, an unnecessary polish on an existing practice only to be used by grifters and wannabe pundits.
Are there grifters? Yes. Absolutely. It’s part of the reason we started Gander.
Rand’s tone and position capitalize on the community’s existing sentiment of skepticism, anxiety, and FOMO. If the Wizard of Moz says them fancy GEO tools is a big ol’ boondoggle, then its gots to be so? Right?
Let’s pull back the curtain a little.
Conflict of Interest
At the beginning of the article, Rand calls out a potential conflict of interest:
“Conflict of interest? Well, maybe, but given my starting point as a devout skeptic, already convinced that AI tracking was a boondoggle, Patrick’s calm demeanor, access to millions of AI response data points, and willingness to leverage his math major background and programming skills made for the perfect research partner.”
It should go without saying that any influencer pieces should have any and all financial relationships, including stake or investment, prominently disclosed. Given Rand’s industry cache, this is an important note. Irrespective of financial ties, Patrick isn’t a disinterested third party, just “helping with research”. He has direct financial incentive and stands to gain from the positioning highlighted in the article—namely that existing tools are inaccurate and expensive.
Rand claims he “hadn’t seen Gumshoe’s product in action before completing 95% of this research work.” Even if true, this is irrelevant. Patrick, who did see the product, was the research partner handling data, programming, and methodology.
Methodology
Rand pre-empts criticism of his methodology by stating he’s not a professional researcher and inviting others to repeat the experiments. Fair enough. This isn’t a peer-reviewed paper and he’s not pretending it is. He is the head of a data company though, has published dozens of studies, and is extremely adept at research.
He does borrow specific techniques: pairwise correlation and semantic similarity scoring, from a Carnegie Mellon paper (Wu et al., EMNLP 2025) that he describes as “a model for this work.” That paper had 2,976 human raters evaluating 14,880 response pairs with formal inter-rater reliability testing, cross-validation, and ethics board approval. Borrowing the methodology implies a degree of rigour. The reader should know the source material was built to a different standard.
Worth noting: the CMU paper’s central finding was that automated consistency metrics don’t align well with human perceptions of consistency and that this gap is worse on real-world prompts than on synthetic ones. That’s directly relevant to every tool in the space, including Patrick’s, since synthetic prompts are the backbone of scaled AI visibility tracking.
Also worth noting: Rand acknowledges brand sentiment briefly but dismisses it. From a GEO perspective, this is a serious omission. A brand appearing in 80% of responses means very little if an LLM consistently frames it with qualifiers like “though some users report quality issues” or “considered a budget option”. Visibility and quality/accuracy are distinct metrics and the study measures only one.
Now, here’s where I’ll probably surprise you—the methodology is largely fine for what it is.
600 volunteers with different devices, settings, chat histories, temperature configurations, and locations. Messy, chaotic, completely uncontrolled. And honestly? That’s what the real world looks like. People don’t standardize their ChatGPT settings before searching for headphones. Rand’s methodology captures a snapshot of the ecosystem. It’s a legitimate choice for a preliminary study.
Where the methodology does fall apart is in the inclusion of Google’s AI Overviews alongside ChatGPT and Claude. AI Overviews are not conversational AI. They’re a search feature embedded in Google’s existing ecosystem, shaped by traditional ranking signals and filtered through Google’s user personalization. They don’t always appear. The same query can trigger an AIO one time and not the next, based on factors that have nothing to do with generative AI consistency. That’s Google’s triggering logic, not LLM behaviour. ChatGPT and Claude always return a response when you ask them a question.
By lumping AIO results alongside ChatGPT and Claude, the study conflates variance caused by generative engine inconsistency (which is what Rand claims to be measuring) with variance caused by Google’s personalization and display logic, which is a different problem entirely.
Most practitioners working in this space already draw a line between conversational AI optimization and AI Overview optimization. They’re related, and the skills overlap, but the measurement challenges are different enough that combining them in a single study muddies the findings. The research would have been stronger, and the conclusions more credible, if AIO had been treated separately.
Core Arguments
Argument 1: AI visibility tools are inaccurate.
By and large, I agree with this argument. My experience conducting competitive intelligence for Gander tells me the same. If you’ve heard me speak or been part of my ongoing industry research, you’ll know I use this example when describing accuracy:
“If five of us ask ChatGPT the same five questions, five times, we’ll get 25 different answers.”
Variability is an understandable part of an optimization practice. Gumshoe’s own blog states:
“We found that individual AI responses are highly variable (you’ll rarely see the same answers twice), but the frequency with which a brand appears across many queries converges to a stable signal.”
The purpose of the article is to showcase that variability is so high that it doesn’t make sense to spend money on a visibility tool. Yet, their own research actually contradicts that statement. Rand opens stating that an estimated $100M+ per year is being spent on AI tracking, with zero published research validating the metrics, and a comparison to “sketchy SEO salespeople” who could weaponize the inconsistency.
His framing is clear: this is an industry selling snake oil to gullible executives.
Before presenting a single number, Rand primes the reader to view every tool, every metric, and every provider through the lens of bad faith. This is a textbook example of poisoning the well. By the time the beautiful graphs appear, the audience has already been told how to feel about them.
Effective rhetoric? Absolutely. A valid, empirical argument? No.
Rand also states: “I could find absolutely no research showing whether AI tools are consistent enough, when prompted for lists of brand/product recommendations, to produce valid visibility metrics.” That may well be true. But the absence of published research proving the metrics work is not the same as evidence that they don’t. There’s no published research disproving them either. The sword cuts both ways.
This is barely a two-year-old industry. SEO didn’t have peer-reviewed validation of domain authority, page rank, or any of its core metrics within its first two years. Even foundational technical SEO elements, like structured data, were widely contested. The gap Rand identifies is real, but it’s an indictment of the research community’s pace, not proof that all practitioners are operating in bad faith.
His research data tells a different story.
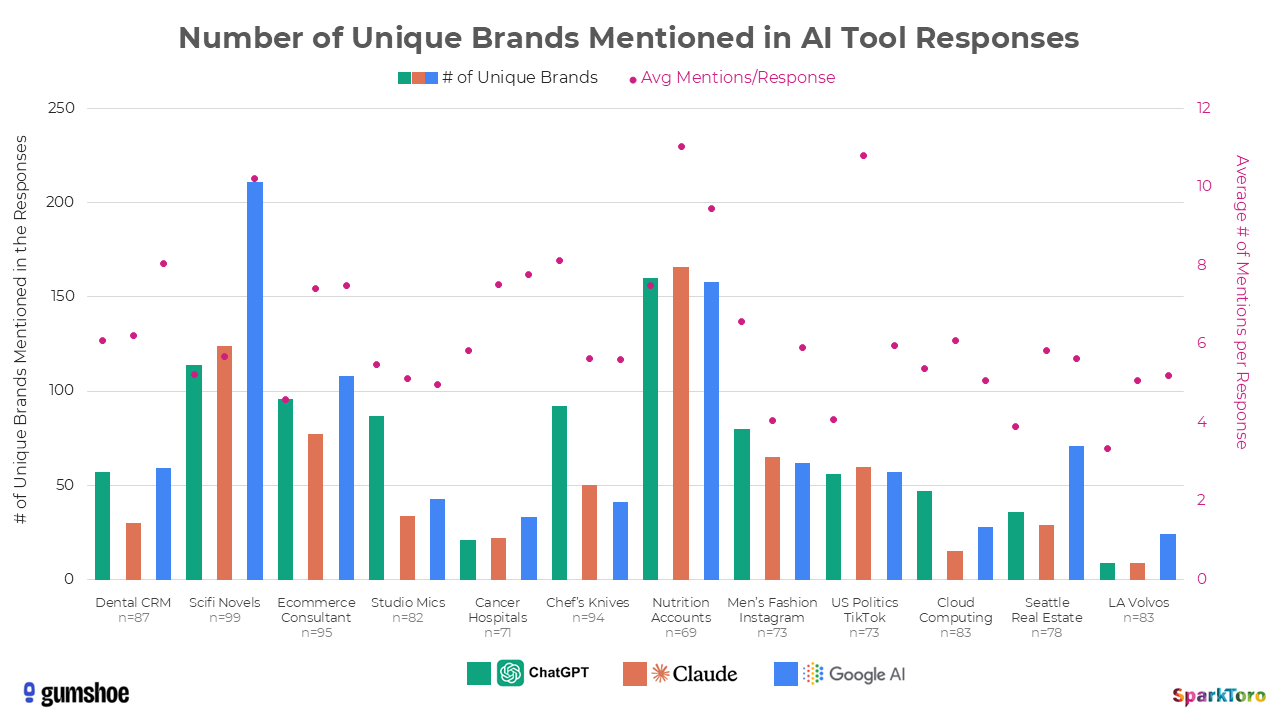
When prompting for recommendations about digital marketing consultants with expertise in e-commerce: Smartsites appears in 85 of 95 responses. Prompting for West Coast Cancer care: City of Hope appears in 69 of 71 responses. Noise cancelling headphones? Bose, Sony, Sennheiser, and Apple appear 55-77% across 994 responses from 142 wildly different human-crafted prompts. His conclusion, in his own words: visibility percentage is “(probably) a reasonable metric.”
And if there were any doubt about how the research was received by his own collaborators, Gumshoe published a blog post two weeks after the article dropped, titled “How Much Data Do You Need to Measure AI Visibility with Confidence?” It opens with “Recent research from SparkToro and Gumshoe” and proceeds to build the statistical foundation for Gumshoe’s product configuration directly on top of these findings.
The research set out to prove AI visibility tracking is a boondoggle. It ended up becoming a product validation exercise for the co-researcher’s company, and each of its “expensive” competitors.
Argument 2: Individual AI responses are effectively random
Rand states that there is a less than a 1% chance that ChatGPT or Google AI will give you the same list of brands in any two responses out of 100 runs. Less than 1 in 1,000 for the same list in the same order. Every response is unique in composition, sequence, and length. His framing: “These tools are probability engines: they’re designed to generate unique answers every time. Thinking of them as sources of truth or consistency is provably nonsensical.”
This is correct. And it’s not new information. Anyone working seriously in this space already knows that individual AI responses are non-deterministic. LLMs operate on token probability distributions. Temperature, sampling methods, and context windows are designed to produce varied outputs. Pointing out that a probability engine produces probabilistic outputs is a description of the architecture.
The implicit comparison here is to traditional search, and it’s doing some heavy lifting. Rand’s audience is SEOs, and the unspoken frame is: imagine if Google gave you completely different results every time you searched. But Google does vary results by personalization, location, device, and search history. The SEO industry didn’t collapse when we discovered that two people Googling the same query see different results. It adapted its metrics. This is the same challenge in a different system.
In the last section, we discussed that there was enormous overlap between these supposedly unique lists. So how can there be less than a 1% chance of getting the same list twice? My hypothesis is that Rand is measuring exact composition matches. If one response returns five brands and the next returns four of the same five, that’s a “different list.” Add one brand, drop another, change the count, it’s now a different list. The 1 in 1,000 stat he presents for order matching is an even stricter condition applied to an already rare subset. Further, we’re seeing a data set where brand presence is consistent but the order in which they’re mentioned is variable.
If the number of brands mentioned is what’s driving classification as unique, and Rand confirms that responses ranged from “as few as 2-3 recommendations, and equally often 10 or more”, then the “chaos” isn’t in which brands the LLM recommends. It’s in how many it decides to mention in any given response. That’s a very different claim than “AI recommendations are random”. Individual responses recommending varying numbers of brands doesn’t invalidate aggregate measurement. Nobody calls polling a boondoggle because each individual response is unpredictable. The signal is in the aggregate. Rand’s own frequency data demonstrates this.
I’d love to verify their findings. The raw data is technically public. Patrick built a mini-site where you can browse responses. But the data isn’t in a format that allows independent reproduction of the 1 in 100 or 1 in 1,000 calculations. The article doesn’t define what constitutes “the same list.” And on their face, these numbers are difficult to reconcile with the frequency data presented in the same article. I’m sure other nerds like me would appreciate seeing your raw data.
EDIT: Our lead AI Engineer, Mehrad, called me out on this argument. His addition:
Your defense of visibility % is built on the observation that the same core brands reliably surface across varied prompts, which is compelling and well-supported. But that consistency actually makes the ordering problem more pointed, not less. If the consideration set is stable, then the rank position isn’t shifting because of noise or small sample sizes. It’s shifting within an otherwise predictable system, which is a stronger argument against rank tracking than Rand’s original framing.
You’re pushing back on the 1 in 1,000 stat as too strict, but you don’t fully reconcile the fact that consistent brand presence and unreliable rank order coexist in the same data.
If certain brands appear consistently across hundreds of responses regardless of how the list is ordered, that consistency is telling you something meaningful about how those brands are represented in the model’s training data or retrieved content. They’ve earned a place in an LLM’s consideration set in a way that others haven’t.
That’s essentially the operational definition of GEO. The goal isn’t to rank 1 in an AI response, the way you’d target position 1 in Google. The goal is to become a brand the model reliably associates with a given intent or topic space, to be in the consideration set at all, and to stay there consistently.
The brands that appear in 80-90% of responses, despite variable ordering, are the case studies that organic search practitioners should study. They’re not gaming a ranking algorithm. They’re genuinely embedded in the model’s understanding of a category.
He’s right. I completely missed that in my original draft. Contrary to traditional SERPs, we have zero evidence that the order in which a brand is mentioned in any given response influences click through. None. Gander does track this as part of its core visibility metrics and it’s largely because our hypothesis is that it will matter in the long term.
The system isn’t random, it’s measurable
Before we get to visibility as a metric, it’s worth pausing on a question Rand never asks: if AI recommendations are essentially random, “spicy autocomplete“, as he puts it, then why do measurable on site quality signals predict citation rates?
Kumar & Palkhouski (2025) audited 1,702 citations across Brave, Google AIO, and Perplexity using 70 B2B SaaS prompts and 1,100 unique URLs. They found that overall page quality predicted citation with an odds ratio of 4.2x. Pages cited by multiple engines scored 71% higher on quality metrics than single-engine citations. The signals that mattered most, metadata freshness, semantic HTML, structured data, were consistent across engines. While I’d like to see ChatGPT, CoPilot, Gemini, Perplexity, and Claude measured, the study’s findings are interesting.
The findings from this study, and others like it, matter because it reframes the question. We’re not asking whether AI outputs are variable, they are. We’re asking whether the system underlying those outputs responds to measurable, optimizable signals. The answer, so far, is yes. Which means the question isn’t “should we track visibility?” It’s “how do we track it well?”
Argument 3: Visibility % is imprecise and requires impractical sample sizes
As I had mentioned earlier on, Rand concedes that visibility percentage is “(probably) a reasonable metric.” He describes it as a “dartboard-pattern-like answer.” When looking at City of Hope’s 97% visibility rate in ChatGPT, he says “I’m not sure it means anything.”
I think it may. When comparing a localized search, such as “best West Coast cancer hospital”, we need to consider that AI search is a more accurate reflection of reality. As early as 2023, Michael King posited that third-party placement is disproportionately weighted in LLM results. This means that LLMs will mine directories with reviews and social media platforms to better understand people’s experience with an organization. Contrast with a more broader topic like best headphones, it may explain why City of Hope has a strong visibility rate in the study.
Strip the rhetorical qualifiers and what remains is straightforward: visibility reported as a percentage works. The study’s data demonstrates convergence across wildly uncontrolled conditions. Gumshoe’s blog post two weeks later didn’t treat it as “probably reasonable”. Instead, they built Bernoulli trial math on top of it and used it to justify their product’s default configuration. You don’t run statistical power calculations on a metric you think is meaningless.
The “dartboard-pattern-like answer” framing sounds damning until you think about what a dartboard pattern actually is. It’s a distribution around a central tendency. That’s how statistical sampling works. Every poll, every clinical trial, every quality control process produces exactly this: variance in individual observations, stability in the aggregate. Calling the output a dartboard pattern describes the metric. That’s what statistics look like.
Now, the sample size question. Rand argues you need 60-100+ runs per prompt to get meaningful visibility data. I agree—it’s why we designed Gander to run more prompts than any other platform. It’s the best argument for automated tooling. No search professional is manually running prompts 100 times, across the most popular four or five engines, and pasting results into a spreadsheet. If visibility as a metric requires scale to be statistically valid, then the solution is a platform that operates at scale.
Now, not every platform is created equal. One of the most popular limits web searches to two (default is between four and six, but can be up to ten), saving them money. Running queries is expensive, and VCs expect a return. What this means is that the results are not indicative of what would be shown to the average person, and query sourcing is limited by more than 50%, conservatively. That is legitimately shady because unless you look under the hood, you’d never know that you’re getting markedly different results.
And let’s be honest about the timeframe here. Rand’s study ran over November and December 2025, which is roughly two months of data collection. Is SEO any different? Has anyone ever looked at two months of organic ranking data and concluded that SEO tracking is a waste of money because positions fluctuate? Of course not. We accept that positions move. We track the trend. We look at visibility over time. This is the same discipline applied to a different system, and the same patience is required.
Where I’ll give Rand credit: his point about accuracy matters. AI tools recommended defunct businesses, inactive social influencers, and non-existent TikTok accounts during this research. That’s a real problem, particularly for branded search where precision matters. Hallucinations are less of an issue than they were a year ago, but they haven’t been eliminated. Any tool tracking AI visibility needs to account for accuracy in responses, not just frequency of mentions and citations or share of voice. That’s a legitimate problem that platforms, and practitioners, need to account for.
Argument 4: Prompt diversity is an unsolved problem that compounds the tracking challenge
Rand asked 142 people to write prompts about the same thing and found the average semantic similarity between their prompts was 0.081. On a scale where 1.0 is identical, that means there’s negligible overlap. He calls synthetic prompts as a proxy for real user queries “a huge problem” and “a giant hole in AI tracking.”
This is genuinely useful data. The industry should pay attention to it. People don’t prompt an LLM the way they search Google. They’re conversational, specific, idiosyncratic, tangential. Many AI visibility platforms organize tracking around keyword clusters, an SEO paradigm that Rand’s own data suggests is not a 1:1 comparable. Search professionals cannot rely on 2-5 keywords as a proxy when writing prompts for their clients.
Despite near-zero semantic similarity in the queries, responses were largely similar when presenting companies, products, and brands. My hypothesis is that intent matters more than the language used in a prompt. Whether a user asks an LLM “What are the best noise cancelling headphones for a flight?” or directs it to “Tell me the best noise cancelling headphones on the market”, I think is less relevant than the purpose of the product—to block out noise while listening to something else. In instances where factors like weight or physical size matter, users will correct and clarify their follow up prompts. Practitioners should be prepared to track follow-up prompts.
If that hypothesis holds, it has significant implications for how we think about tracking. It means organizing measurement around topics and intents rather than specific query strings isn’t just practical, it’s how the models themselves operate. And it means the prompt diversity “problem” isn’t a hole in AI tracking. It’s evidence that generative engines are more robust than the surface-level variation suggests.
The parallel to traditional search is worth noting. Long-tail keyword diversity has always been a challenge in SEO. Millions of unique queries, infinite variation. Nobody concluded that because users search in wildly different ways, tracking organic visibility was pointless. The industry built tools that clustered queries by intent and measured visibility at the topic level. This is the same problem in a new system, and it calls for the same solution.
Argument 5: The burden of proof is on the tools, and they aren’t meeting it
Rand closes with a call to action: stop paying for AI tracking tools that don’t publish transparent, publicly reviewable research. He lists open questions: minimum sample sizes for statistical significance, API vs. web interface scraping, prompt diversity requirements, and frames them as preconditions the industry hasn’t cleared. His message to buyers: demand proof or walk away.
He’s right. The industry should be more transparent. Published methodologies, public data, reviewable research. If you’re charging marketers thousands per month to track something, you should be able to show your math. Fighting this point would look defensive, and it would be wrong. The call for transparency is the strongest and most constructive part of the entire article.
There’s an irony here. Rand just demonstrated that the first person to actually do the research validated the practice. The burden of proof argument works if the evidence, once gathered, shows the tools are broken. His own evidence showed the opposite. He set out to prove AI visibility tracking is an expensive waste of time, gathered data, and concluded that visibility percentage is meaningful, if done well. The burden was met. By him. The answer wasn’t the one his headline promised.
The unanswered questions he lists are real. But they’re operational, not existential.
- How many runs do you need for statistical significance?
- How closely do API calls mirror web interface results?
- What diversity of prompts is required for a given sector?
These are calibration questions, not evidence that all tools are fundamentally flawed. Every measurement discipline has open methodological questions. SEO has been debating the validity of domain authority for a decade. That didn’t stop anyone from tracking organic visibility.
One piece of rhetoric worth noting: “If Patrick and I can do it in our spare time while running multiple companies, you know who else can do it?” This simultaneously positions the research as a casual side project, lowering the bar for methodological scrutiny, and shames venture-backed companies for not publishing their own work. Both framings can’t hold at the same time. Either this kind of research requires rigorous, well-funded effort, or it’s something two busy guys can knock out between D&D sessions. The industry deserves the former, and the standard should apply evenly. Hell, I’m pretty busy building a bootstrapped AI analytics platform and found the time to read his study, corresponding research, and write a rebuttal.
Parting Thoughts
What’s surprising is the question that Rand doesn’t ask: does increased visibility predict business outcomes?
His research validates that visibility % is measurable. It shows the metric is statistically consistent across varied conditions. It never asks whether that metric correlates with anything that matters: traffic, brand awareness, pipeline, revenue. Does a 97% visibility rate translate into more patients calling City of Hope? Does Smartsites appearing in 85/95 of responses drive inbound leads? We don’t know, because the research stops at “the number is real” and never gets to “the number is useful.”
That’s the actual open question for this industry, and it’s bigger than anything in this article.
About the Author: Adam Malamis
Adam Malamis is Head of Product at Gander, where he leads development of the company's AI analytics platform for tracking brand visibility across generative engines, like ChaptGPT, Gemini, and Perplexity.
With over 20 years designing digital products for regulated industries including healthcare and finance, he brings a focus on information accuracy and user-centered design to the emerging field of Generative Engine Optimization (GEO). Adam holds certifications in accessibility (CPACC) and UX management from Nielsen Norman Group. When he's not analyzing AI search patterns, he's usually experimenting in the kitchen, in the garden, or exploring landscapes with his camera.

{kind=link}
{kind=link}
{kind=link}
{kind=link}